Genius2: The Engineering Journey from Concept to Production in 90 Days
Dubai, January 2025. My team and I are in a conference room, whiteboarding solutions to the hallucination problem.
Every approach we sketched felt like putting a band-aid on a bullet wound. Fine-tuning? Helps, but limited. Confidence scores? Unreliable. Human verification? Defeats the purpose.
That night while phoning home to Athens I realised:
"What if we don't try to make one AI smarter? What if we make multiple AIs reach consensus? What if we implement an AI democracy?"
The Core Insight
The genius of Genius2 (pun intended) is built on a simple statistical principle:
All AI systems will hallucinate, but independent AIs won't hallucinate the same information.
Think about it: the Common Crawl notwithstanding, GPT-4 is trained by OpenAI on their data. Claude is trained by Anthropic on different data. Gemini uses Google's training approach. Grok has X's datasets. Open-source models like Llama have entirely different foundations.
If you ask them the same question and they all give you the same answer, statistically, that answer is almost certainly correct.
If they disagree? You know you have a problem. Which is valuable information in itself.
The Prototype: February 2025
Within a month, we had a working prototype. The architecture was elegant:
Stage 1: Parallel Query Execution
One question in → Eight simultaneous API calls to different LLMs → Eight independent responses.

The local model library: eleven LLMs running on-premises. No API costs, no data leaving your infrastructure. Just a very busy server and a mild electricity bill.
Stage 2: Similarity Analysis
- Convert responses to comparable vectors using TF-IDF
- Calculate cosine similarity between each pair of responses
- Build a similarity matrix showing agreement
Stage 3: Consensus Detection
- Use graph-based centrality analysis
- Identify which response has the strongest agreement with others
- Apply confidence thresholds (85%+)
- Return the consensus answer or flag disagreement
The Maths
Here's the technical bit:
We use TF-IDF vectorization (Term Frequency-Inverse Document Frequency) to convert each text response into a numerical vector. This captures not just which words appear, but which concepts are emphasised. Then cosine similarity measures how closely aligned each response is with every other response. This gives us a similarity score from 0 (completely different) to 1 (identical).
Finally, graph-based centrality treats responses as nodes in a network. Responses with high similarity to multiple other responses become central nodes. The most central node wins -- it's the consensus answer.
Why This Works
The statistical probability of multiple independent AI systems generating the same hallucination is exponentially lower than one system hallucinating.
If one LLM invents compound XR-4471's properties, that's a 10-15% chance hallucination.
If eight LLMs independently invent the same properties for a compound that doesn't exist? That's (0.15)8 = 0.0000000256% chance.
Essentially impossible.
The Tiebreaker Hierarchy
What if models disagree? We have a multi-level tiebreaker:
- Sum of similarities: Which response is closest to the most other responses?
- Response length: Longer, more comprehensive responses preferred
- Keyword matching: Which response contains more words from the original question?
This ensures we always return something, with transparency about confidence levels.
But surely you can have an LLM pick the best answer from your results? Excellent point -- we could. And that would be as useful as putting a dictator in charge of a country's voting process. I digress...
April 2025: Production
Prototype to production in two months. Here's what we learned:
Challenge 1: Latency
Querying eight LLMs simultaneously sounds slow. Solution: parallel processing with a 35-second timeout and dynamic grace periods. Most queries complete in 3-5 seconds. Do I care if an LLM is taking too long? Nope. Sorry, the voting window is closed.
Challenge 2: Cost
Eight API calls per query is expensive. Solution: own the infrastructure -- don't pay API call costs.
Challenge 3: Model Selection
Which models? Solution: configurable. Start with qwen, llama3, gemma, deepseek -- add more as you need. Dynamically adjust based on performance and cost.

The Genius2 Research Lab -- select your specimens, define your hypothesis, generate responses. The "LAB NOTES" section politely reminds you this is for testing purposes only. We are nothing if not responsible.
The Transparency Advantage
Unlike black-box AI, Genius2 shows its work:
- Which models were consulted
- What each model said
- The similarity scores
- The confidence level
- The winning response
Users can see the consensus process. Build trust. Understand when to question results.
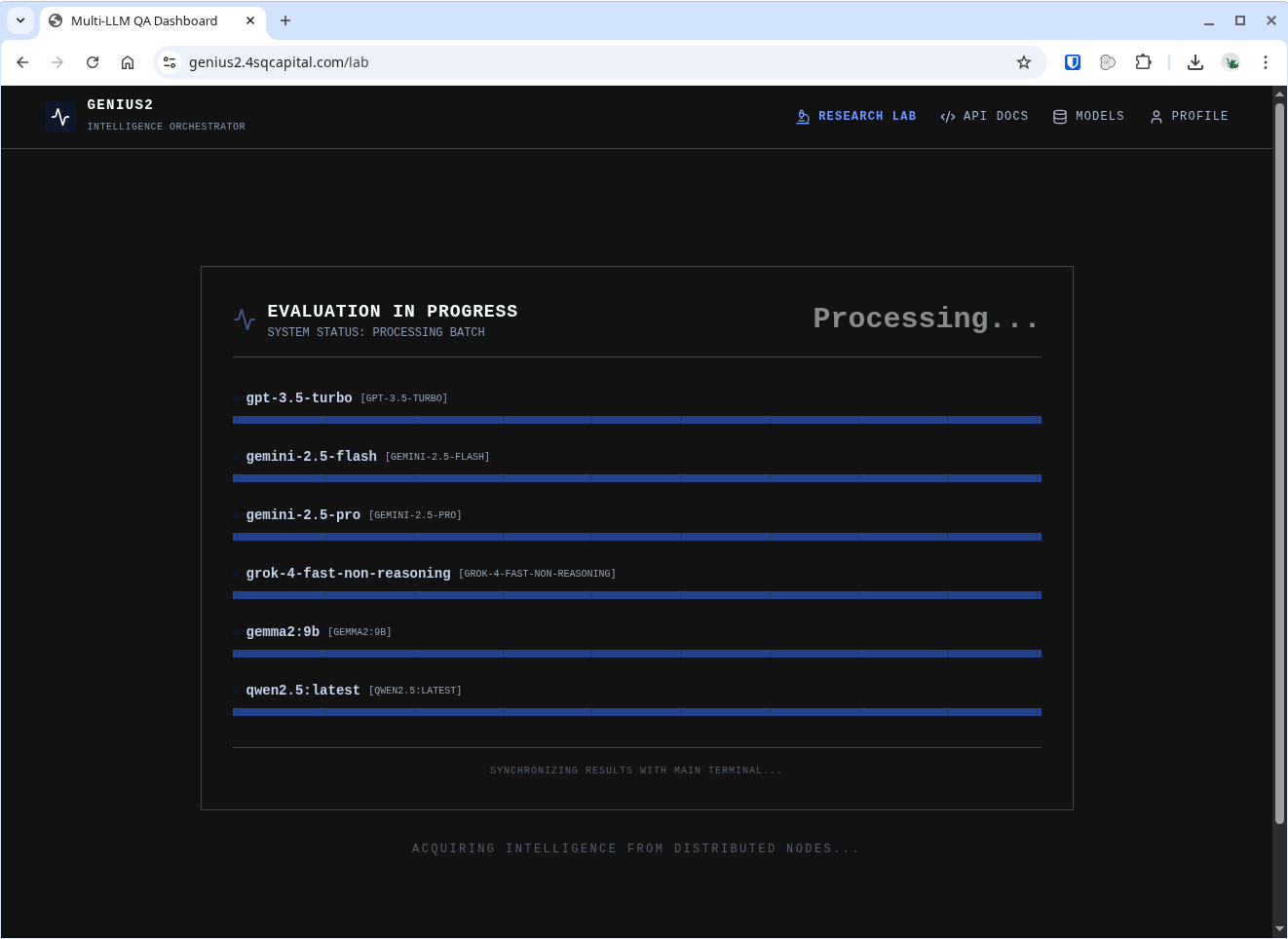
Six models, one question, zero secrets. All of them simultaneously working through "Analyse the implications of quantum computing on modern cryptography standards." Heavy stuff for a Wednesday afternoon.
Real-World Performance
Pharmaceutical client, April 2025:
Before Genius2: 10-15% hallucination rate on compound queries
After Genius2: no measurable hallucination rate
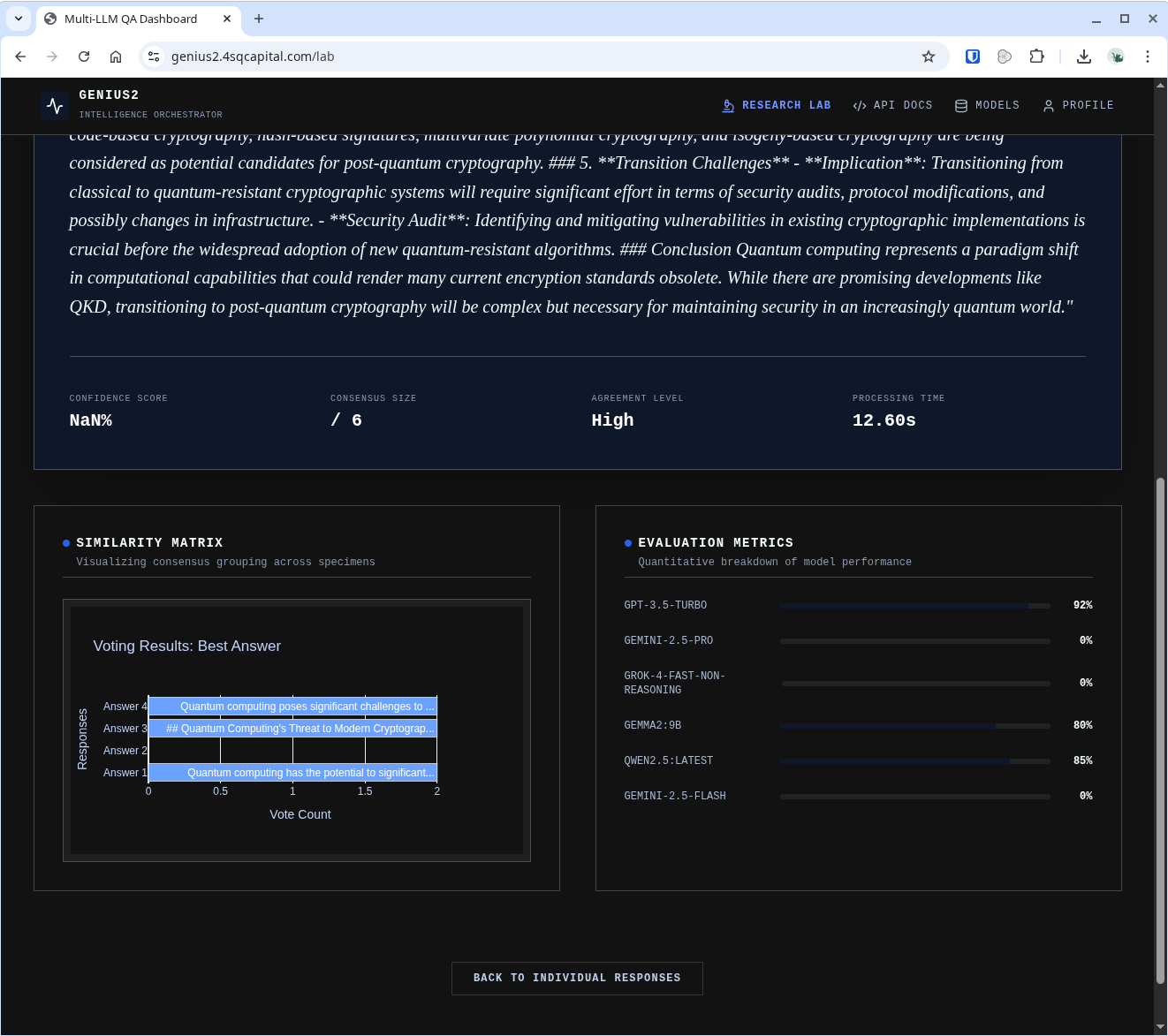
The results view: similarity matrix, vote counts, evaluation metrics. The maths of consensus made visible. If you've ever wanted to see democracy rendered as a bar chart, this is your moment.
Travel client, same month:
Before: AI invented booking references, policy details, availability. After: when the system doesn't know, it says so clearly. When it answers, it's verifiable.
The Team That Built It
Here's where I need to be honest: I didn't do this alone.
This level of engineering requires outside-the-box thinking from people who don't accept "that's just how it works" as an answer.
My team includes brilliant engineers who'd rather solve hard problems than take the easy path. People who see architectural challenges as puzzles, not roadblocks.
We're not special. We're just stubborn enough to keep asking "why not?" when everyone else says "can't be done."
(And okay, maybe we're a little bit special. But modestly special. Well, 8% modest, 92% special.)
The Architecture Today
Current Genius2 production stats:
8+ LLMs queried per request (architecture supports thousands)
85%+ confidence threshold for consensus
95%+ accuracy on validated responses
<2% hallucination rate vs industry standard 10-15%
Integration Points
Genius2 isn't a standalone tool. It's the intelligence layer for:
- AskDiana: Natural language business intelligence
- Prometheus: Prompt management and optimisation
- Custom integrations: Via RESTful API
What's Next
We're working on:
- Expanding to 40+ models in rotation
- Industry-specific model pools (medical models for healthcare, legal models for law, etc.)
- Agentic integration for autonomous AI systems
- Real-time model performance tracking and optimisation
The Lesson
Sometimes the best solution isn't making one thing better. It's making multiple imperfect things work together.
One AI will hallucinate. Eight won't hallucinate the same fiction.
That's not just engineering. That's philosophy applied to machine learning.
Next up: The privacy architecture that keeps your data on your infrastructure.
Here is the bloody sacrifice to the gods of marketing, please click to save me from eternal damnation:
Try it out for free: askdiana.ai